Simple Masked Training Strategies Yield Control Policies That Are Robust to Sensor Failure
Skand Peri, Bikram Pandit, Chanho Kim, Li Fuxin, Stefan Lee, CoRL 2024
Abstract
Sensor failure is common when robots are deployed in the real world, as sensors naturally wear out over time. Such failures can lead to catastrophic outcomes, including damage to the robot from unexpected robot behaviors such as falling during walking. Previous work has tried to address this problem by recovering missing sensor values from the history of states or by adapting learned control policies to handle corrupted sensors through fine-tuning during deployment. In this work, we propose training reinforcement learning (RL) policies that are robust to sensory failures. We use a multimodal encoder designed to account for these failures and a training strategy that randomly drops a subset of sensor modalities, similar to missing observations caused by failed sensors. We conduct evaluations across multiple tasks (bipedal locomotion and robotic manipulation) with varying robot embodiments in both simulation and the real world to demonstrate the effectiveness of our approach. Our results show that the proposed method produces robust RL policies that handle failures in both low-dimensional proprioceptive and high-dimensional visual modalities without a significant increase in training time or decrease in sample efficiency, making it a promising solution for learning RL policies robust to sensory failures.
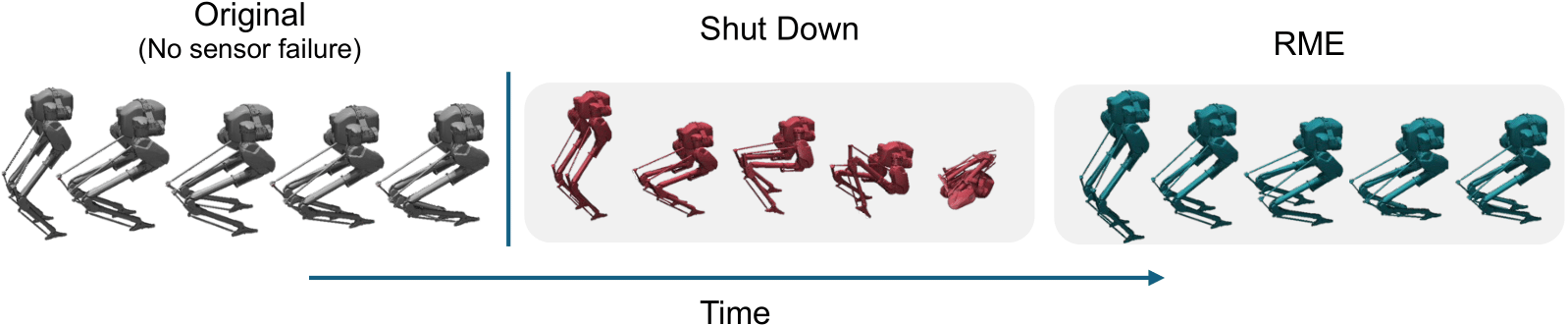
Robust Multimodal Encoder (RME)
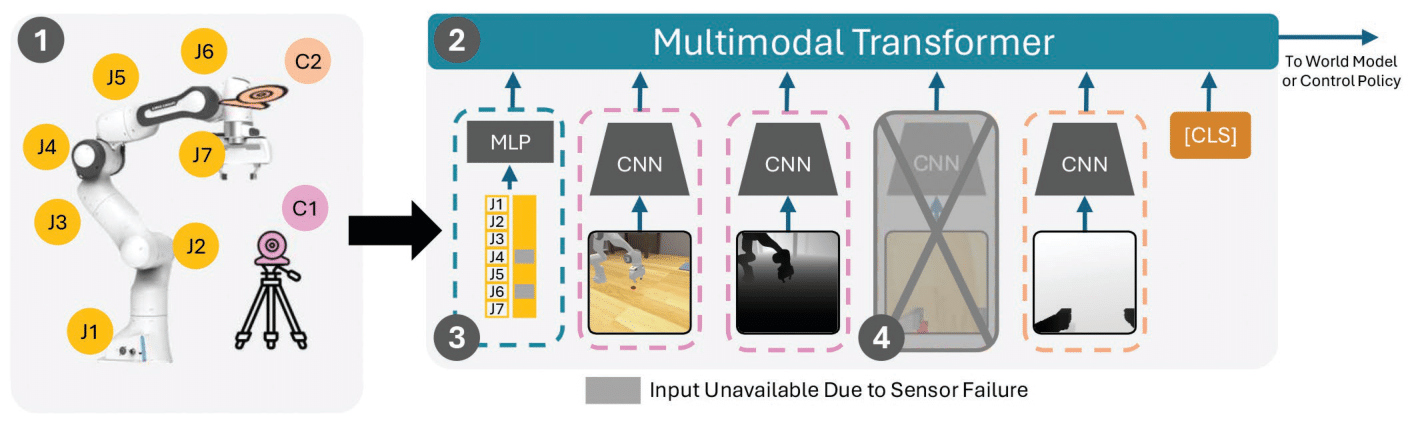
Robust Multimodal Encoder (RME): We propose a simple, yet effective modification to learn robust representations within existing RL frameworks. (1) We consider each robot sensor as a modality that can be potentially missing during deployment. (2) The proposed RME architecture con- sists of both low-dimensional proprioceptive inputs as well as high dimensional image inputs that are encoded using appropriate encoders (MLP, CNNs) and fed into a transformer. We employ different dropout mechanisms for low and high dimensional modalities. (3) Given the proprioceptive (or any other low-dimensional) input, we append a mask vector where 1/0 indicate the presence/absence of the sensor respectively. (4) For high-dimensional modalities, we simply drop the modality shaded in gray while training.