Non-conflicting Energy Minimization in Reinforcement Learning based Robot Control
Abstract
Efficient robot control often requires balancing task performance with energy expenditure. A common approach in reinforcement learning (RL) is to penalize energy use directly as part of the reward function. This requires carefully tuning weight terms to avoid undesirable trade-offs where energy minimization harms task success. In this work, we propose a hyperparameter-free gradient optimization method to minimize energy expenditure without conflicting with task performance. Inspired by recent works in multitask learning, our method applies policy gradient projection between task and energy objectives to derive policy updates that minimize energy expenditure in ways that do not impact task performance. We evaluate this technique on standard locomotion benchmarks of DM-Control and HumanoidBench and demonstrate a reduction of 64% energy usage while maintaining comparable task performance. Further, we conduct experiments on a Unitree GO2 quadruped showcasing Sim2Real transfer of energy efficient policies. Our method is easy to implement in standard RL pipelines with minimal code changes, is applicable to any policy gradient method, and offers a principled alternative to reward shaping for energy efficient control policies.
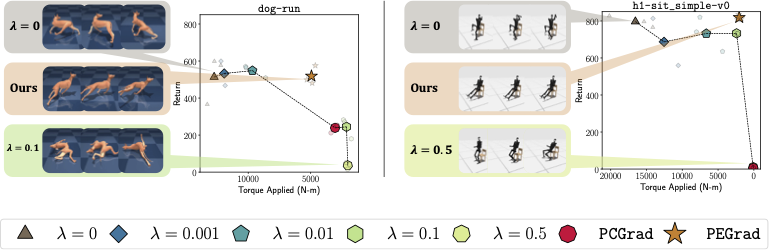
dog-run task, \(\lambda=0.01\) and \(\lambda=0.1\) result in significantly different performance -- with the policy at \(\lambda=0.1\) achieving low returns by crawling rather than running. However, \(\lambda=0.1\) works well in the less dynamic dog-walk environment (Not shown). (Right) For a humanoid sitting task, both \(\lambda=0.01\) and \(0.1\) yield policies that are equally energy-efficient and task-effective, showcasing the inter-environment variability. In both cases, our proposed hyperparameter-free method, PEGrad(\(\bigstar\)), leads to performant and energy efficient policies. Projecting Enery Gradients PEGrad
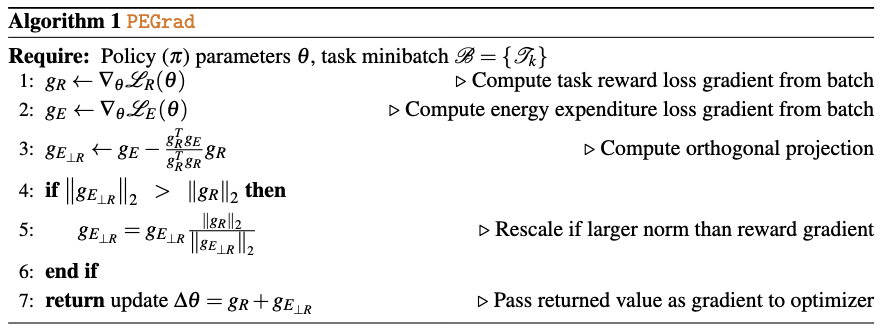
Results on DMControl (Medium and Hard tasks)
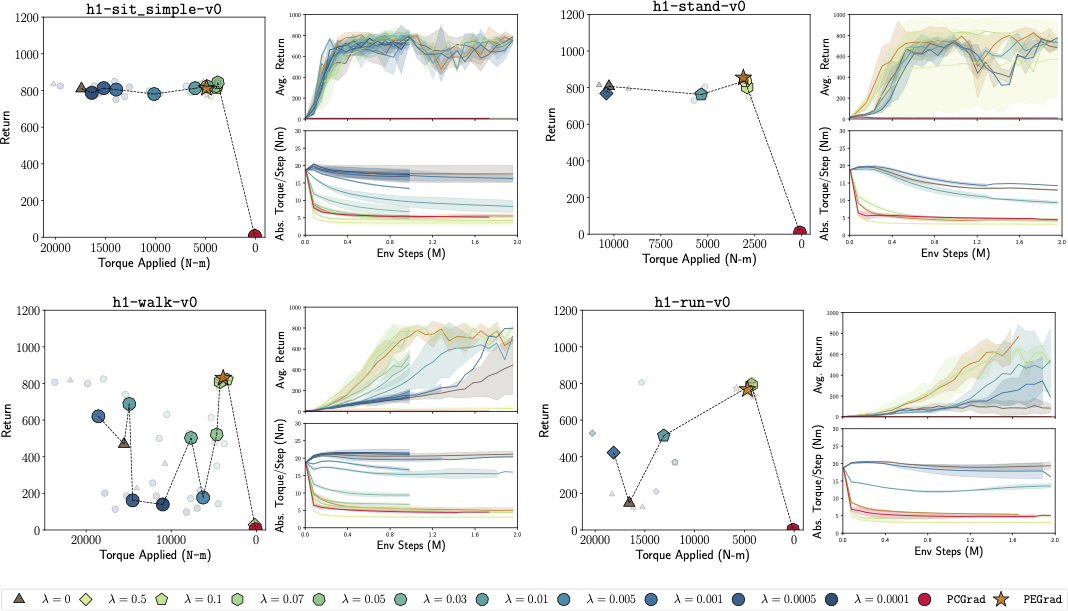
Results on Humanoid-Bench
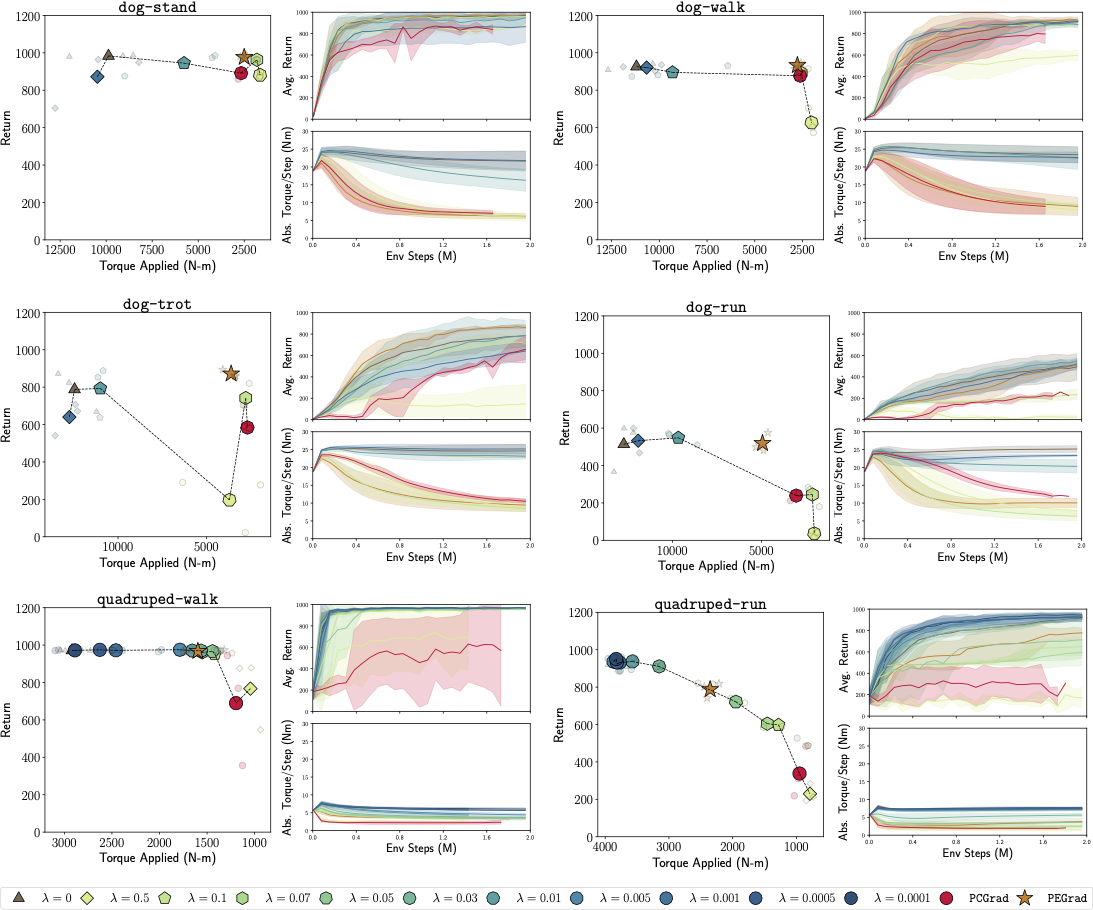
Sim2Real Quantitative Results