Point Cloud Models Improve Visual Robustness in Robotic Learners
Skand Peri, Iain Lee, Chanho Kim, Li Fuxin, Tucker Hermans, Stefan Lee, ICRA 2024
Abstract
Visual control policies can encounter significant performance degradation when visual conditions like lighting or camera position differ from those seen during training – often exhibiting sharp declines in capability even for minor differences. In this work, we examine robustness to a suite of these types of visual changes for RGB-D and point cloud based visual control policies. To perform these experiments on both model-free and model-based reinforcement learners, we introduce a novel Point Cloud World Model (PCWM) and point cloud based control policies. Our experiments show that policies that explicitly encode point clouds are significantly more robust than their RGB-D counterparts. Further, we find our proposed PCWM significantly outperforms prior works in terms of sample efficiency during training. Taken together, these results suggest reasoning about the 3D scene through point clouds can improve performance, reduce learning time, and increase robustness for robotic learners.
Point cloud world models
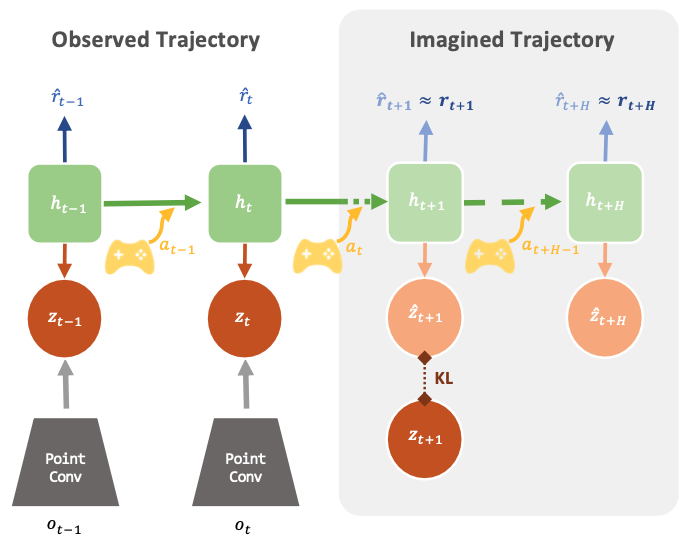
Given a sequence of \(T\) partial point cloud observations, we encode them using a PointConv encoder. For each timestep \(t\), we compute a posterior stochastic latent \(z_t\) using an encoding of \(o_t\) and hidden state \(h_t\) that encodes the history. The hidden state is further used to compute the prior latent which is used to predict multi-step rewards over a horizon \(H\) providing supervision for the world model along side temporal consistency with KL loss.
Experiments
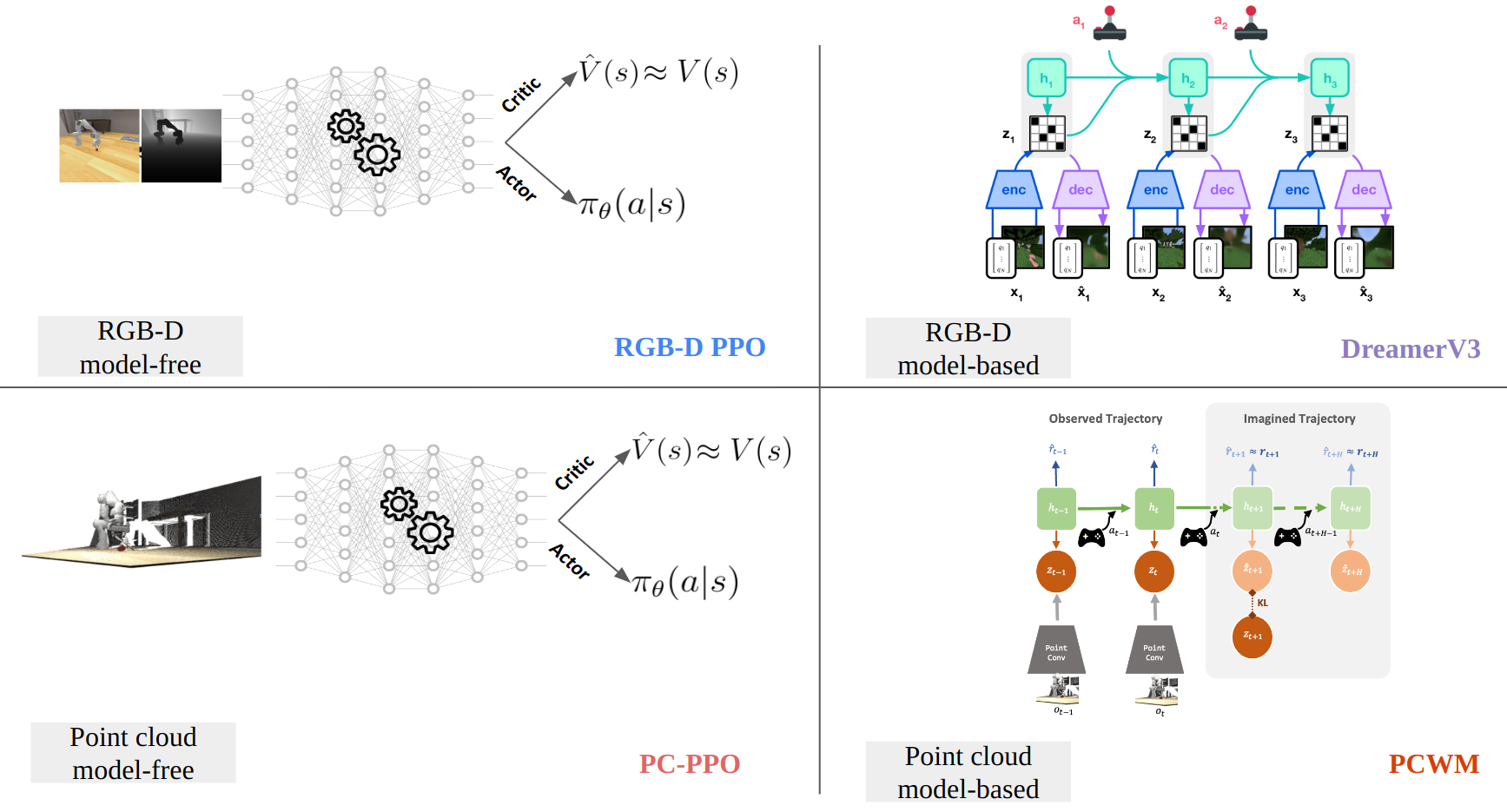
We compare 4 models (a) model-free RGB-D [RGB-D PPO], (b) model-free point cloud [Point cloud PPO], (c) model-based RGB-D [DreamerV3] and (d) model-based point cloud [PCWM].
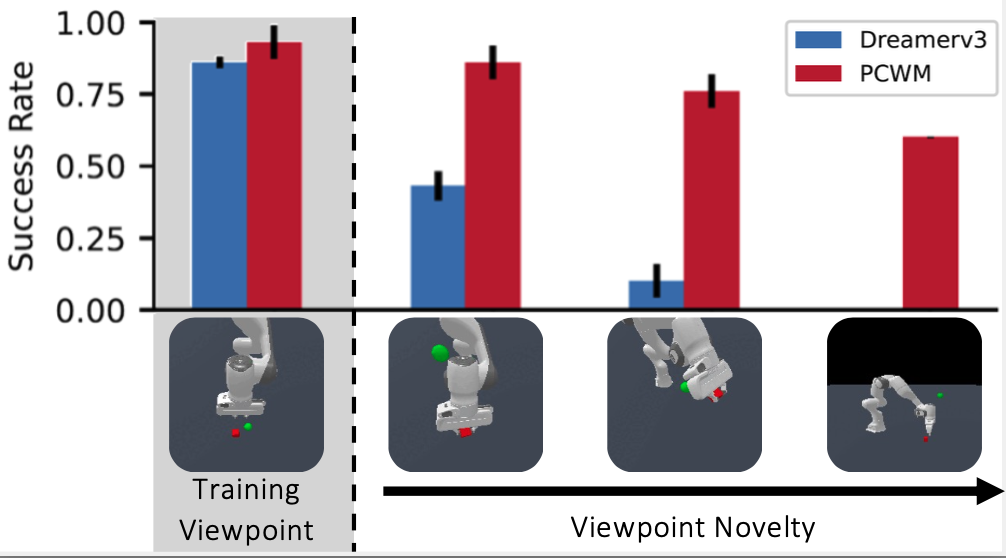
Robustness towards viewpoint changes (Pitch)






Robustness towards viewpoint changes (Yaw)


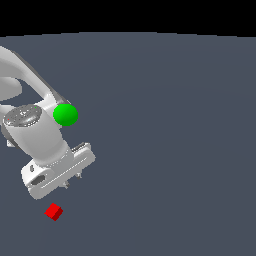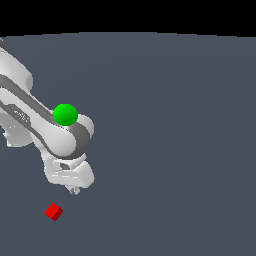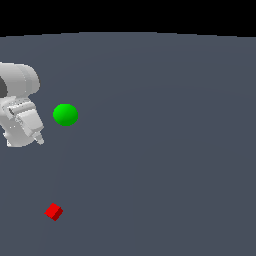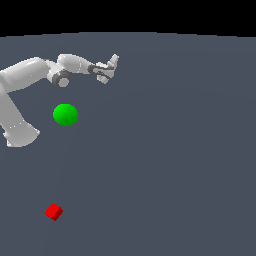



Robustness towards Lighting Changes